
Mick is tired of the lockdowns.
Category Archives: Information
Charts
Proof of America’s decline?
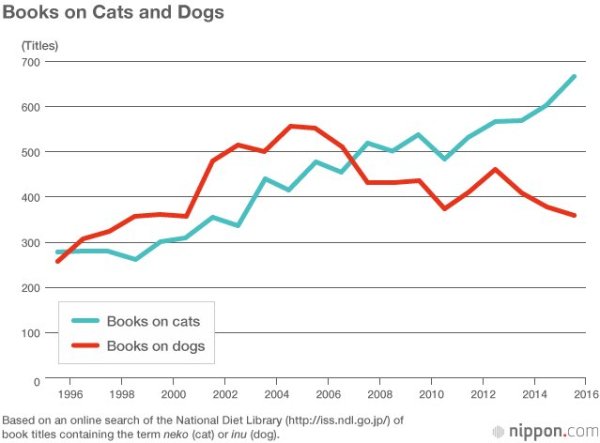
Always label your axes.

Free speech rankings
Free speech rankings are out (NCSU was not part of the survey). Three NC / ACC schools (Duke, UNC, Wake) were ranked. Wake, at #47 out of 55, is rated “yellow.” I wonder where we would rank.
IoT is awful
Gizmodo has an article on a hacked coffee maker. IoT devices are poorly made and vulnerable.
Quote of the Day
The only person you are destined to become is the person you decide to be.
— Ralph Waldo Emerson